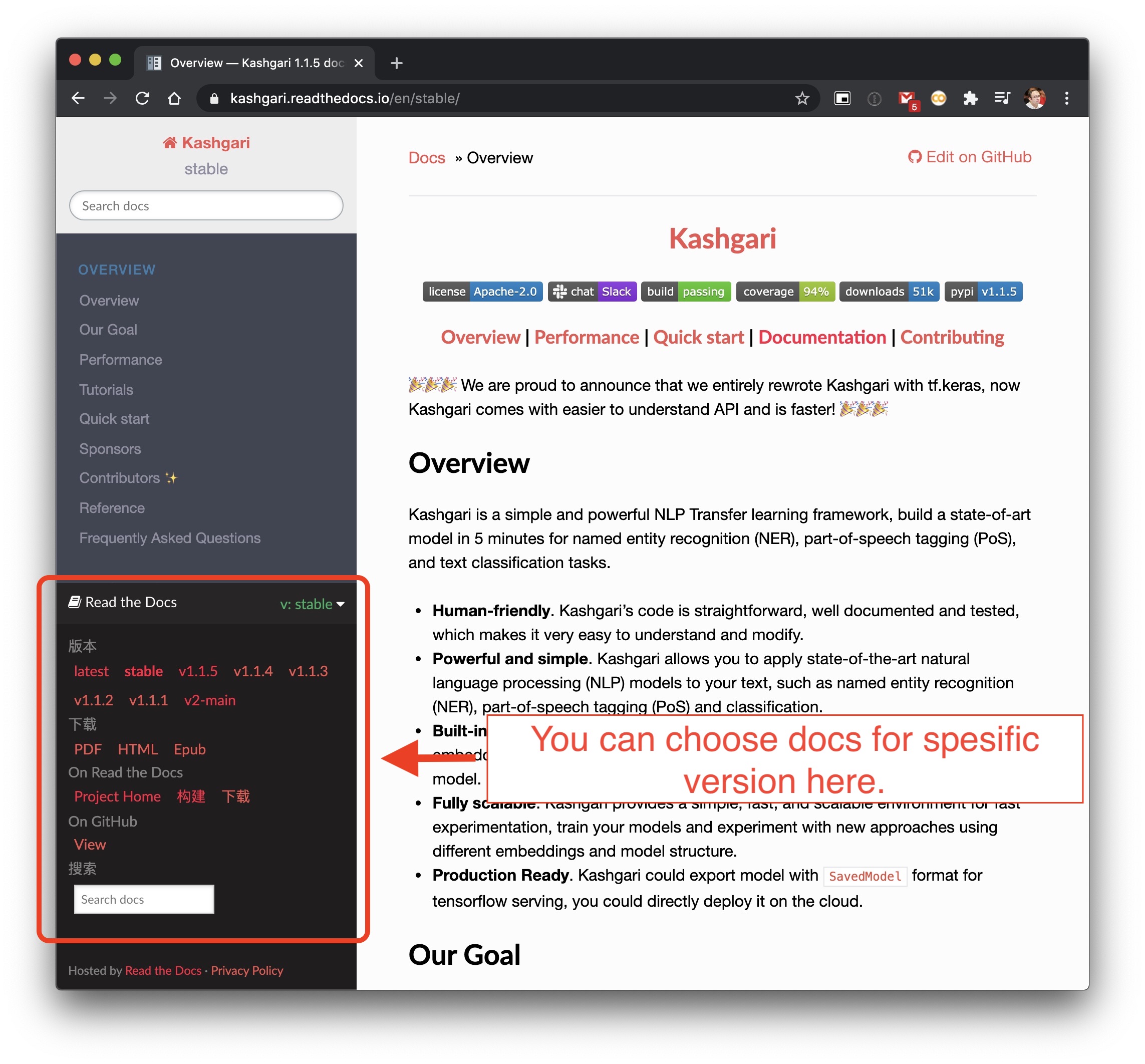
Welcome to Kashgari Documents Documents migrated to ReadTheDoc. 文档已迁移至 ReadTheDoc, 请按照版本查阅。 Kashgari V1.x docs Kashgari V2.x docs